
I am a postdoctoral researcher at the Autonomous Vision Group lead by Andreas Geiger, part of the Intelligent Systems department of the Max-Planck Group. Previously, I finished my PhD at Ghent University (Belgium), working on the entire imaging chain for 3D reconstruction. During this time, I had the pleasure to intern at the Bell Labs (then Alcatel, now Nokia) in Antwerps, as well as with the Autonomous Vision Group I am now part of.
In this phd thesis, we examine the entire 3D reconstruction chain, spending due time on both the calibration process (for various camera models), as well as the reconstruction step. We give an overview of the various 3D reconstruction techniques, and situate all the previous research within the 3D reconstruction framework. I was awarded the title ‘Doctor of Computer Science Engineering’ at Ghent University after succesfully defending this work in front of an academic jury.

Stationarity of reconstruction problems is the crux to enabling convolutional neural networks for many image processing tasks: the output estimate for a pixel is generally not dependent on its location within the image but only on its immediate neighbourhood. We expect other invariances, too. For most pixel-processing tasks, rigid transformations should commute with the processing: a rigid transformation of the input should result in that same transformation of the output. In existing literature this is taken into account indirectly by augmenting the training set: reflected and rotated versions of the inputs are also fed to the network when optimizing the network weights. In contrast, we enforce this invariance through the network design. Because of the encompassing nature of the proposed architecture, it can directly enhance existing CNN-based algorithms. We show how it can be applied to SRCNN and FSRCNN both, speeding up convergence in the initial training phase, and improving performance both for pretrained weights and after finetuning.

A linear, or 1D, camera is a type of camera that sweeps a linear sensor array over the scene, rather than capturing the scene using a single impression on a 2D sensor array. They are often used in satellite imagery, industrial inspection, or hyperspectral imaging. In satellite imaging calibration is often done through a collection of ground points for which the 3D locations are known. In other applications, e.g. hyperspectral imaging, such known points are not available and annotating many different points is onerous. Hence we will use a checkerboard for calibration. The state-of-the-art method for linear camera calibration with a checkerboard becomes unstable when the checkerboards are parallel to the image plane. Our proposed method yields more accurate camera calibrations without suffering from this shortcoming.

Stereomatching is an effective way of acquiring dense depth information from a scene when active measurements are not possible. So-called lightfield methods take a snapshot from many camera locations along a defined trajectory (usually uniformly linear or on a regular grid-we will assume a linear trajectory) and use this information to compute accurate depth estimates. However, they require the locations for each of the snapshots to be known: the disparity of an object between images is related to both the distance of the camera to the object and the distance between the camera positions for both images. Existing solutions use sparse feature matching for camera location estimation. In this paper, we propose a novel method that uses dense correspondences to do the same, leveraging an existing depth estimation framework to also yield the camera locations along the line. We illustrate the effectiveness of the proposed technique for camera location estimation both visually for the rectification of epipolar plane images and quantitatively with its effect on the resulting depth estimation. Our proposed approach yields a valid alternative for sparse techniques, while still being executed in a reasonable time on a graphics card due to its highly parallelizable nature.

At the HiPEAC Computing Systems Week in the fall of 2016, students from over the world were challenged to efficiently implement n-body system simulations. We chose to do this within the Quasar framework, which is a high-level language that automatically generates efficient CUDA code. At the time, Quasar had just gained the capability to coordinate multiple GPUs, and in this presentation we outline how to efficiently divide the large point clouds using octrees, and how to divide those efficiently over multiple GPUs.

In order to efficiently study the impact of environmental changes, or the differences between various genotypes, large numbers of plants need to be measured. At the VIB (Flemish Institute for Biotechnological research), a system named PhenoVision was built to automatically image plants during their growth. This system is used to evaluate the impact of drought on different maize genotypes. To this end, we require 3D reconstructions of the maize plants. Over several submissions and presentations we outline how our system achieves this efficiently.
In the end we have a mix of careful calibration, machine learning for segmentation, voxel carving for rough cloud reconstruction, and subsequently a particle system for the leaf tracing and finally a bezier fitting to selected leaf candidates. Over the fitted leaves, we also model their width. In the end, we can automatically measure leaf lengths and areas for the plants, as fast as the PhenoVision system is able to image them.
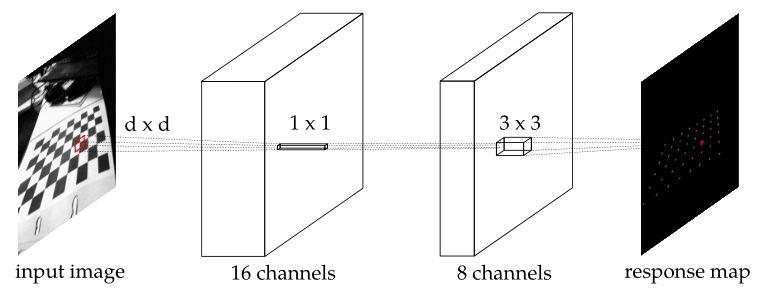
The problem of camera calibration is two-fold. On the one hand, the parameters are estimated from known correspondences between the captured image and the real world. On the other, these correspondences themselves—typically in the form of chessboard corners—need to be found. Many distinct approaches for this feature template extraction are available, often of large computational and/or implementational complexity. We exploit the generalized nature of deep learning networks to detect checkerboard corners: our proposed method is a convolutional neural network (CNN) trained on a large set of example chessboard images, which generalizes several existing solutions. The network is trained explicitly against noisy inputs, as well as inputs with large degrees of lens distortion. The trained network that we evaluate is as accurate as existing techniques while offering improved execution time and increased adaptability to specific situations with little effort. The proposed method is not only robust against the types of degradation present in the training set (lens distortions, and large amounts of sensor noise), but also to perspective deformations, e.g., resulting from multi-camera set-ups.
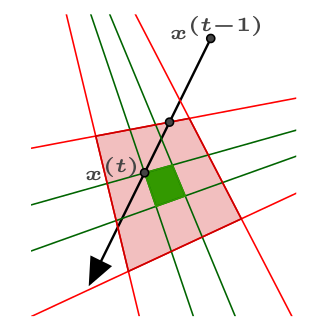
Multi-camera triangulation of feature points based on a minimisation of the overall L2 reprojection error can get stuck in suboptimal local minima or require slow global optimisation. For this reason, researchers have proposed optimising the L-infinity norm of the L2 single view reprojection errors, which avoids the problem of local minima entirely. In this paper we present a novel method for L-infinity triangulation that minimizes the L-infinity norm of the L-infinity reprojection errors: this apparently small difference leads to a much faster but equally accurate solution which is related to the MLE under the assumption of uniform noise. The proposed method adopts a new optimisation strategy based on solving simple quadratic equations. This stands in contrast with the fastest existing methods, which solve a sequence of more complex auxiliary Linear Programming or Second Order Cone Problems. The proposed algorithm performs well: for triangulation, it achieves the same accuracy as existing techniques while executing faster and being straightforward to implement.
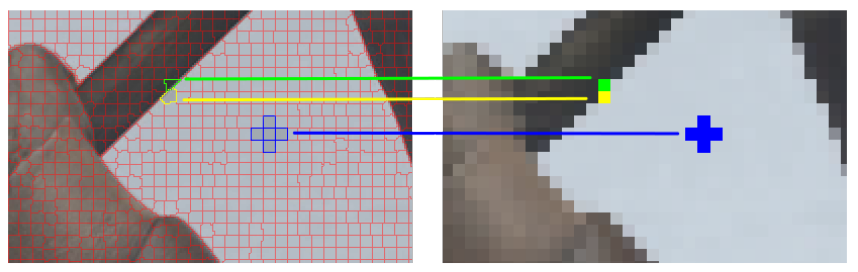
We show how pixel-based methods can be applied to a sparse image representation resulting from a superpixel segmentation. On this sparse image representation we only estimate a single motion vector per superpixel, without working on the full-resolution image. This allows the accelerated processing of high-resolution content with existing methods. The use of superpixels in optical flow estimation was studied before, but existing methods typically estimate a dense optical flow field – one motion vector per pixel – using the full-resolution input, which can be slow. Our novel approach offers important speed-ups compared to dense pixel-based methods, without significant loss of accuracy.

In two-view stereo matching, the disparity of occluded pixels cannot accurately be estimated directly: it needs to be inferred through, e.g., regularisation. When capturing scenes using a plenoptic camera or a camera dolly on a track, more than two input images are available, and - contrary to the two-view case -pixels in the central view will only very rarely be occluded in all of the other views. By explicitly handling occlusions, we can limit the depth estimation of a pixel to only use those cameras that actually observe it. We do this by extending variational stereo matching to multiple views, and by explicitly handling occlusion on a view-by-view basis. Resulting depth maps are illustrated to be sharper and less noisy than typical recent techniques working on light fields.
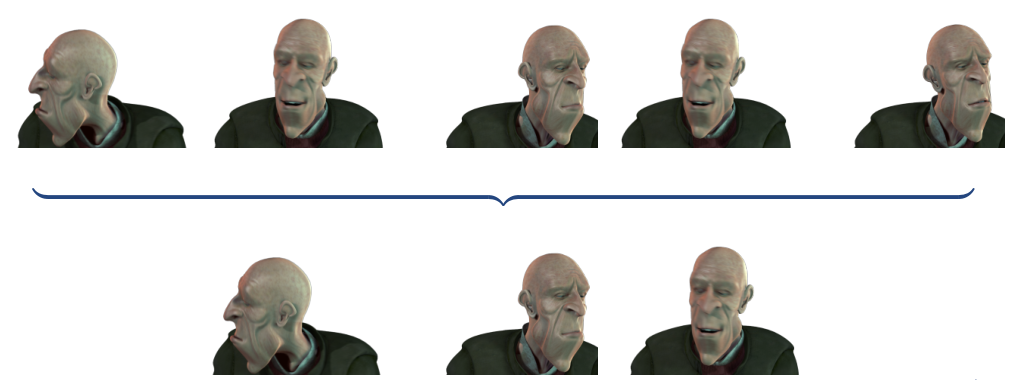
When we wish to apply non-rigid structure-from-motion to on-line video sequences, in which we need to learn the shape basis on the fly, then pre-existing techniques break down. They estimate the shape basis from a large video in one go, and it is not immediately obvious how to compact an existing video in order to enable much more efficient estimation of the shape basis (after which incoming frames can be processed one-by-one). In this work we outline an approach that compacts all previously seen frames into a small keyframe set, bridging the gaps between existing techniques and on-line/real-time processing.

I am still actively researching various topics, so stay tuned for more work! Research overview coming soon.
If you have any questions, proposals or other comments of a different nature, you are welcome to contact me by e-mail.